
什麼是語料庫?
語料庫(corpus,複數為corpora)與文件集(document set)在Concise裡頭是同樣的概念,指的是用來解決您資訊需求的素材,或是您感興趣的目標文本。必須先有素材存在,才有可能進行接下來的分析。
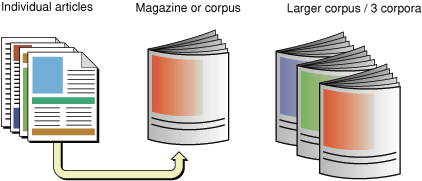
所有素材、文本的集合就是語料庫。您可以將語料庫想像為一本雜誌,這本雜誌是由許多個別的文章組成的。這時,個別的文章就是語料庫中的文件(document),而這本文件集合的雜誌就是個語料庫。如果將單位改變,把一本雜誌所有的內容作為一個文件,那麼雜誌的集合就成了一個更大的語料庫。

Corpus Manager 用是相同的概念,每一列都是一份文件。這些文件集合成了Concise的語料庫。您可以將Corpus Manager視為雜誌的目錄,雙擊其中的文件,或是按右鍵選擇「開啓 Open」,就能打開Document Viewer檢視文件的內容。
Concise 是如何建構語料庫的?
用Concise來建構語料庫並不複雜,只要點選「匯入 Import」,選取要匯入的檔案,稍微調整一下自訂詞庫,接下來都交給Concise去處理。

然而,在這個簡單的步驟後頭,語料庫的建構涉及幾個概念:分詞(tokenisation)、標註(tagging)與索引(indexing)。
中文分詞
分詞(tokenisation)指的是將文件中原始的詞彙轉為控制的詞彙。簡單的說,就是處理怎麼樣才算是一個詞彙(word)的問題。對英文,或是用空白字元作為間隔的語系來說,這個問題會稍微簡單一些,但是仍得要處理多樣詞形是否要還原為基本詞形的問題。舉例來說,過去式、進行式與未來式是否要還原為簡單現在式,是否要保留所有格等問題。
中文對時態與所有格並沒有那麼敏感,但是詞彙的邊界卻是個大問題。中文字指的是「字元」(char)的概念,但語料庫中重視的卻是詞彙(token或word)。詞彙可能僅有一個中文字,或是由兩個以上的中文字構成。要怎麼樣將一連串的中文句子斷成一個個有意義的詞彙,一直是讓許多中文的使用者或開發者頭痛的部分。
目前找得到,並且原本就以繁體中文為基礎建構的分詞系統,大概就是中央研究院中的中文斷詞系統。可惜的是這個系統並不是開源的,當然背後的詞庫與分詞的依據,全都只能仰賴該小組發表的論文。對一般的分詞需求可能足夠了,但是特殊主題(如農業、旅遊、美食等)的應用,特別是專有名詞的處理上就顯得有些不足。
目前比較常見的Java開源分詞軟體大概有下列幾個:ik-analyzer、ICTCLAS、mmseg4j、庖丁解牛、fudannlp、smallseg、lingpipe和Standford Word Segmenter。以上所有的分詞軟體用的都是用簡體中文的詞庫,或用簡體中文詞庫訓練出來的模型。儘管這些模型可以用在繁體,但是效果並不怎麼好。
然而其中的mmseg4j,應用了蔡志浩的MMSEG演算法,只要將裡頭的詞庫與中文字的機率檔案代換,即可應用於繁體中文。同時,也方便特殊主題的使用者新增自訂詞庫。這個便利的特性符合Concise的需求,因而在修改了mmseg4j原始碼讓它也能拋出標點符號後,成為Concise的中文分詞核心。
標註(tagging)
不同的研究目的會需要不同的標註方式,最常見的標註是詞性(part-of-speech)。根據不同的目的,有時還會對類碼(lemma,或稱還原詞形)、分類、命名實體(named entity)進行標註。有的研究將標註視為分詞的一部份。
Concise 從 0.3.6 之後,在匯入文件時增加詞性標註的功能。詞性最重要的功能,依舊是區別詞彙的不同意義。在中文裡頭,同樣的詞彙在不同的句子或是文脈中,經常有不同的作用。有時候可以當作名詞,有時候又作為副詞或是形容詞。詞性的標註有助於消彌這些詞彙在文脈中的歧義性。

然而就如同中文分詞的系統,詞性標註的開源程式依舊缺乏繁體中文的模型。好在繁體中文與簡體中文極為相似,句法在某種程度上是可以共通的。因而可以運用簡體中文訓練出的詞性標註模型,直接對分過詞的繁體中文進行詞性標註。
Concise選擇的是 Stanford NLP 中的 Part-Of-Speech Tagger,用的模型是賓州大學的中文句結構樹(CTB, Chinese Tree Bank)所訓練出來的。詞性的說明可以在這裡下載。
索引(indexing)
索引可以讓應用程式快速找到搜尋的目標,但索引的方式直接影響搜尋的結果。很多搜尋系統在建構索引的時候會略過標點符號與停用詞(stop words),認為這些資訊對搜尋結果是冗贅的。但是Concise對空白字元(空格、tab、斷行符號)外的所有詞彙(包括標點符號)進行索引,讓使用者在後續的操作中,根據其目的自行選擇要顯示的詞彙與停用詞。
Concise在0.3.0之後採用Apache Lucene Core作為索引與搜尋的核心,這個核心在許多專案中都能見到。語料庫匯入Concise之後,相關的索引也會一併完成。藉著索引中儲存的資訊,讓Concise能較為快速地找尋並顯示結果。
一旦建構了語料庫,就可以依據不同的搜尋、呈現、與過濾方式,提取文本中的訊息。從最基本的脈絡化關鍵詞(Keyword in context)、詞彙的計數,到具備簡單統計功能的詞語共現(collocation)和語料庫語言學的關鍵詞(Keyword),甚至是視覺化的文本探索,Concise試圖用簡便的方式讓使用者/研究者能夠從不同的角度看待他們的文本。
- 下載 Concise (http://concise.sustudio.org/p/download.html)